SPSS 작업형 실습공부_(1)~(5)
사회조사분석사 2급 작업형 실습 첫번째 동영상입니다.
반드시 1-5의 사용자 이름 영문으로 되어야 합니다.
수록내용:
1. 데이터 다운로드
2. SPSS 옵션 설정
4단계: 탭만 체크하고 공백이랑 콤마는 해제
3. 데이터 불러오기
3-1. 인코딩 변경 후 불러오기 (데이터 불러오기 오류 해결법 포함)
3-2. 메모장에서 불러오기
Ctrl A +, Ctrl + C => 우클릭 후 변수명 붙여넣기
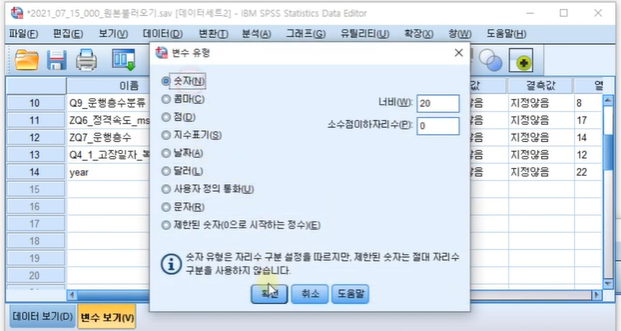
4. 변수보기를 활용한 소수점 변경 및 유의점
문자너비는 50으로
수치형 데이터는 소수점 2으로 바꾸기
사회조사분석사 2급 작업형 실습 두번째 동영상입니다.
수록내용:
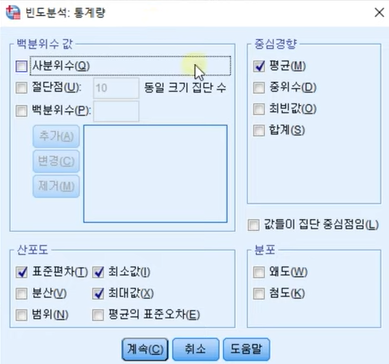
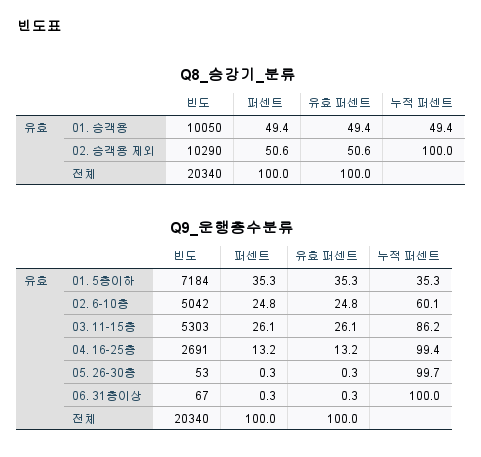
1. 빈도분석 (빈도분석 시 유의점)
출력결과
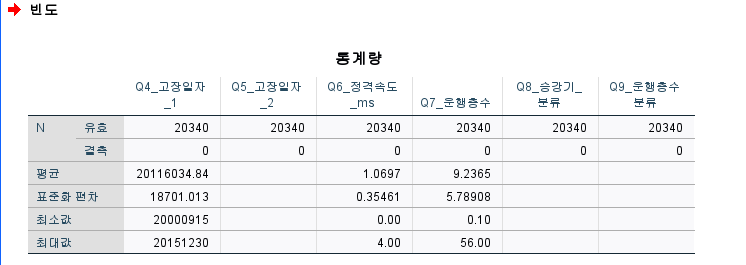
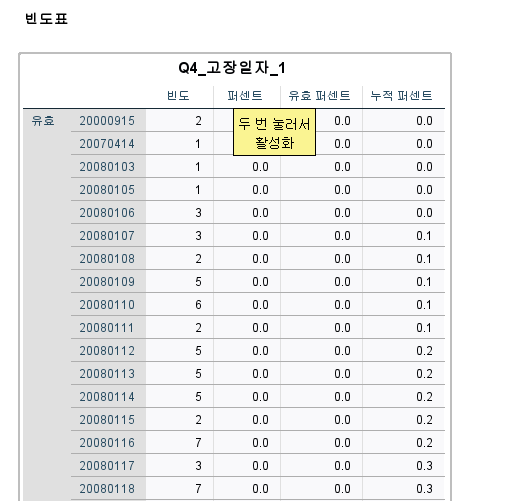
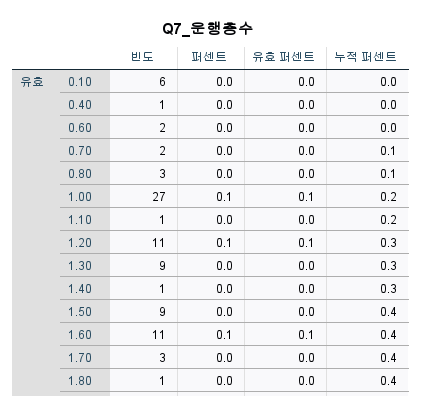
ㄴ> 운행층수=연속형 변수이므로 빈도분석으로 결과 도출어려움
2. <0.001로 나올때 해결하기 03:51
더블클릭->드래그 잡아댕긴 상태에서오른쪽 더블 클릭하면
소수점 끝까지 확인하여 이걸로 답안작성하기
3. 결과표에서 소수점 변경하기 04:40
1)드래그 후 오른쪽 마우스 클릭-> 셀 특성-형식값-소수점 이하 조정
2)표에서 길이 늘리기
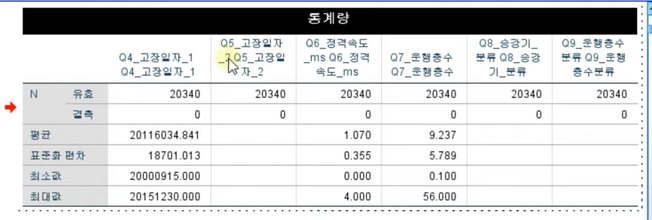
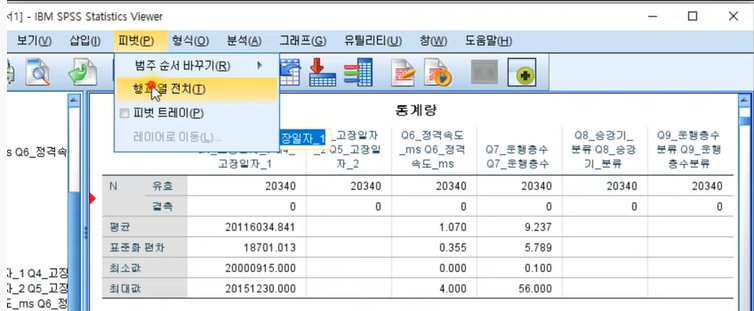
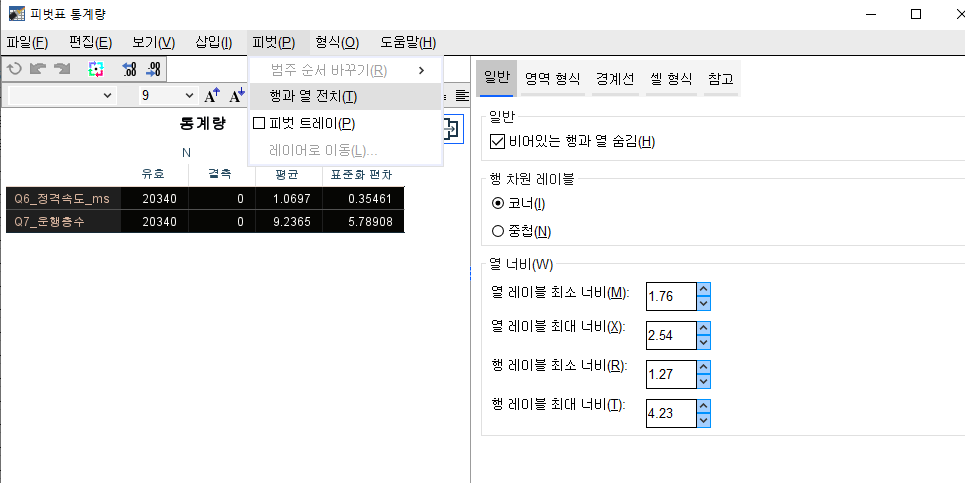
4. 결과표 행렬변경(피벗) 하기 05:40
더블클릭 -> 피벗- 행열전치
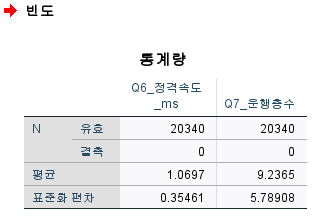
5. 기술통계와 빈도분석 차이점 06:24
빈도분석: 사분위수 구하기O, 문자형은 화면상에 출력O
기술통계: 사분위수 구하기X, 문자형은 화면상에 출력X
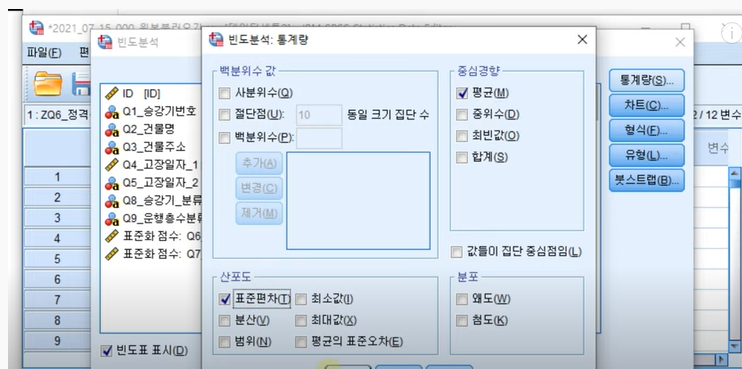
분석-기술통계량-기술통계
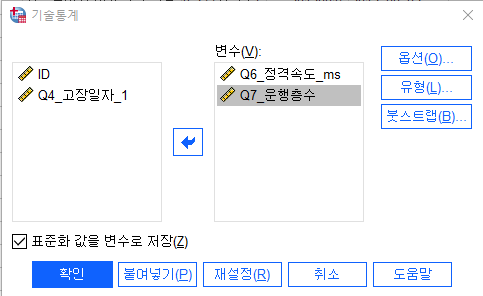
변수설정-> 옵션 -> 표준화 값을 변수로 저장(Z)
새롭게 표준화를 새롭게 생성
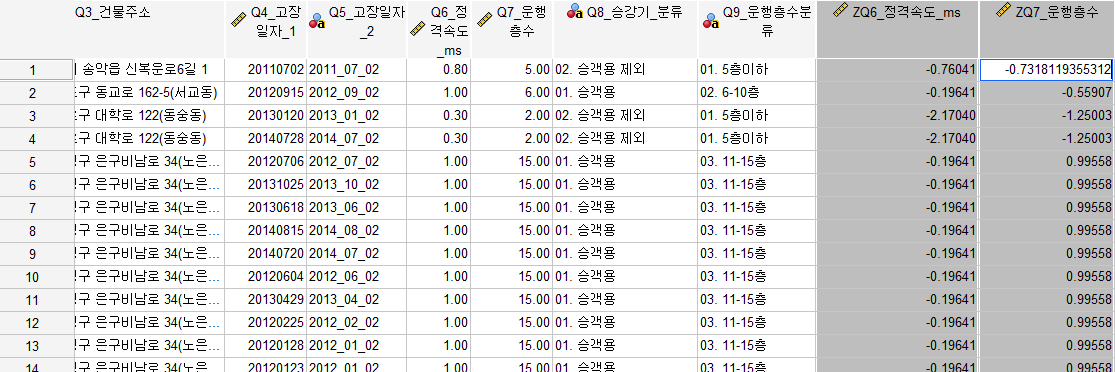
변수보기의 측도부분은 손대지 않아도된다
표준편차/평균을 구하려고 할때
1) 드래그 후 해당 부분 복사 후 새로운 데이터 파일에 붙여넣기
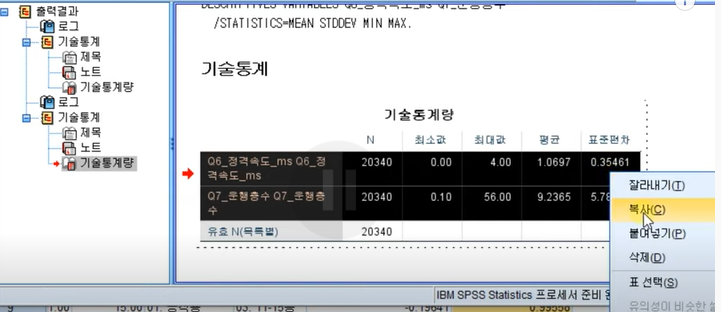
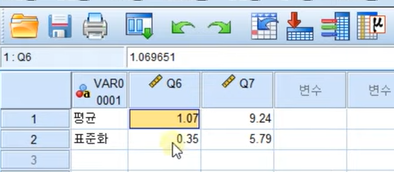
6. 결과표 피벗 변경 실습 및 활용하기 07:45
컬럼과 컬럼으로 구성해야하므로 피벗으로 행열바꾸기해야함
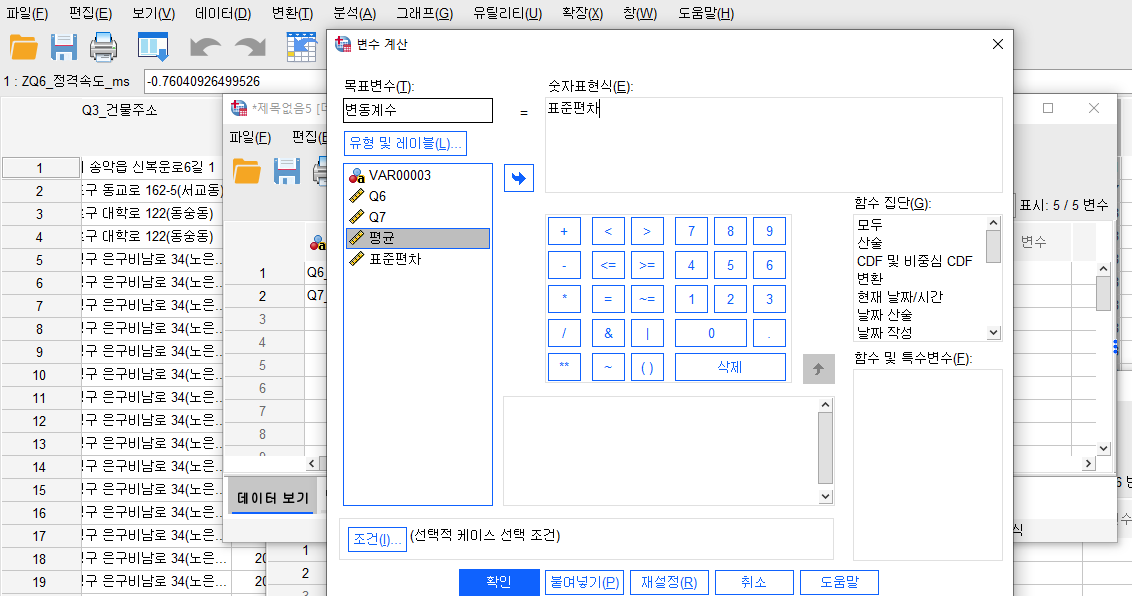
7. 변수계산 시 소수점 증가해야 하는 이유 09:33

8. 변수계산 실습하기 (변동계수 산출) : 12:35
변환-변수계산
목표변수에 변동계수로 기록하고
- 표준편차가 위이므로 숫자표현식(E)에 표준편차 넣기
- 평균이 밑이므로 유형 및 레이블(L)에 평균 넣기
사회조사분석사 2급 작업형 실습 세번째 동영상입니다.
수록내용:
1. 텍스트 나누기
해당 부분을 복사한 후
다른 곳에 붙여넣기
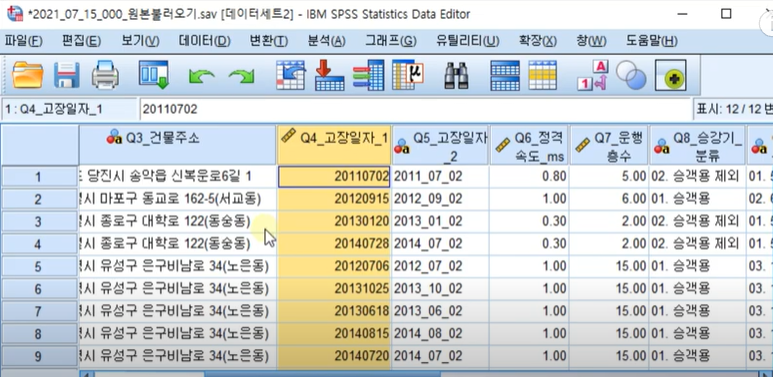
숫자형-> 문자형으로 변경
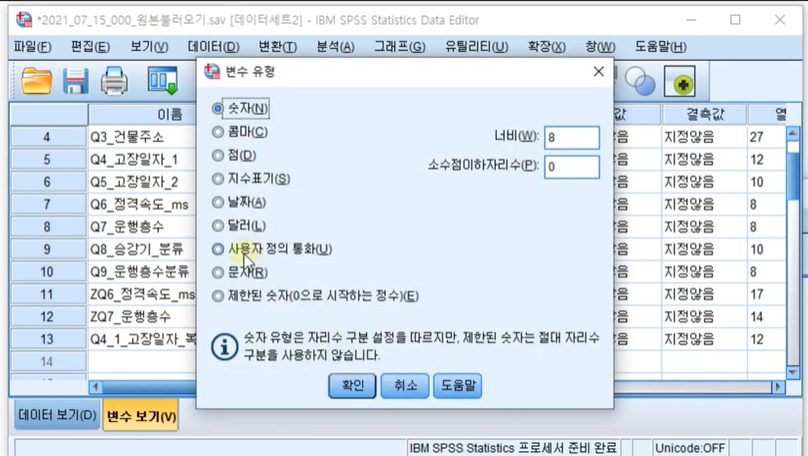
1-1. char.substr(3): 두 해당연도 사이
목표변수: year
함수집단: 모두-char.substr(3) 선택
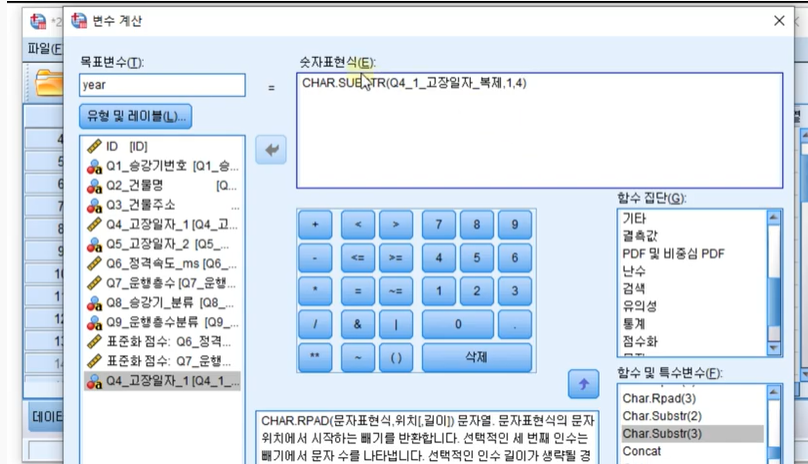
각각 ?부분에 채우기
유형 레이블-문자로 변환 후, 너비를 20으로 변환
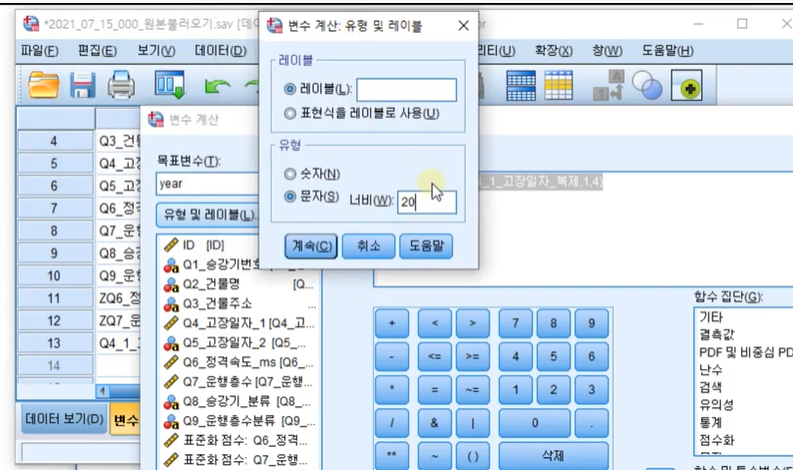
문자형-> 숫자형으로 변경하면
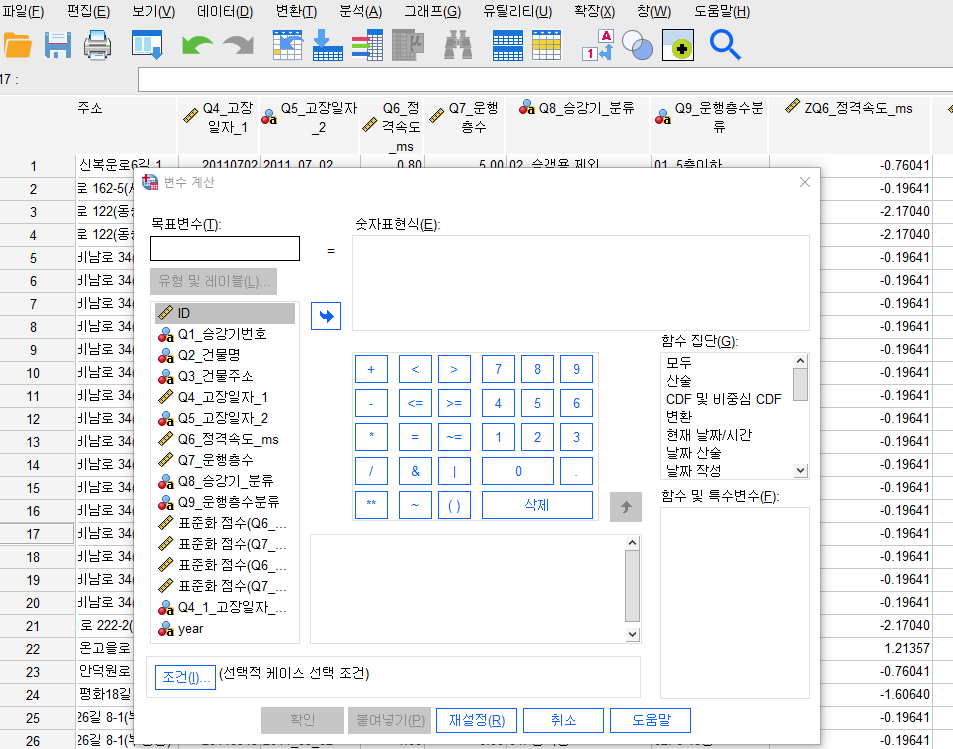
1-2. char.substr(2): 해당되는 연도 이후
다시 계산식을 만들 때
변환-변수 계산 재설정
목표변수: date
함수집단: 모두-char.substr(2) 선택
5번째이후 컬럼부터 쭉
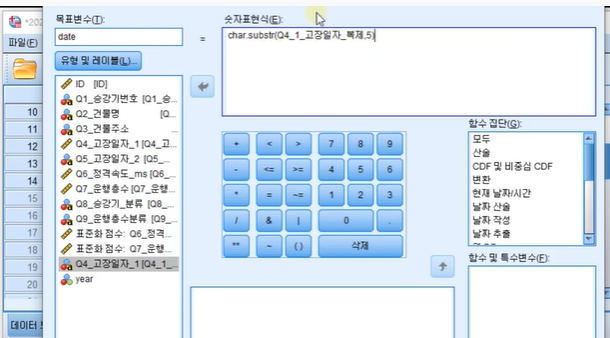
유형 레이블-문자로 변환 후, 너비를 20으로 변환
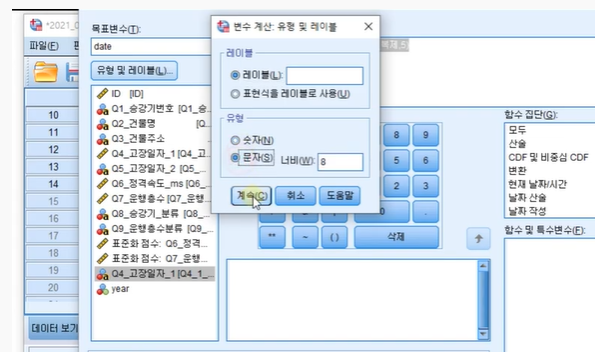
숫자순서 유의하기 R은 0부터 시작
재설정 후
목표변수: month
함수집단: 모두-char.substr(3) 선택
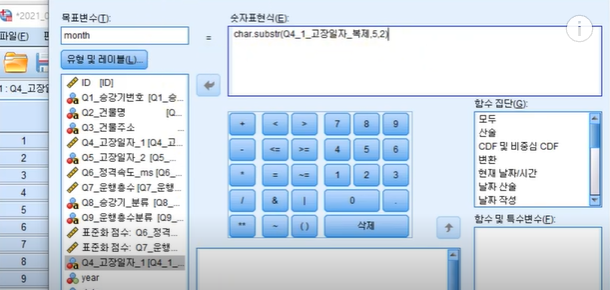
원래대로는 좌로 밀착숫자로 변환하면 우로 밀착
2. 텍스트 합치기 07:45
2-1. concat
변수와 변수합치기/자르기= 변수를 문자로 바꿔서 합쳐야함
변환-변수계산-재설정
뒤에 부분이 다 잘나오지 않는 경우
문자형 자릿수 50까지 늘린다
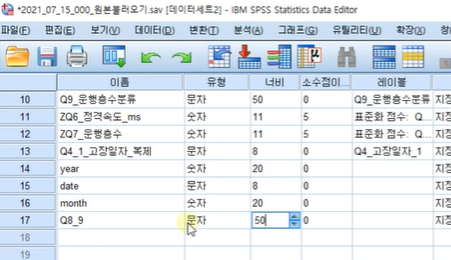
그래도 잘 안나타나는 경우는 해당 부분에
문자외에 다른 것이 들어갔기 때문이므로
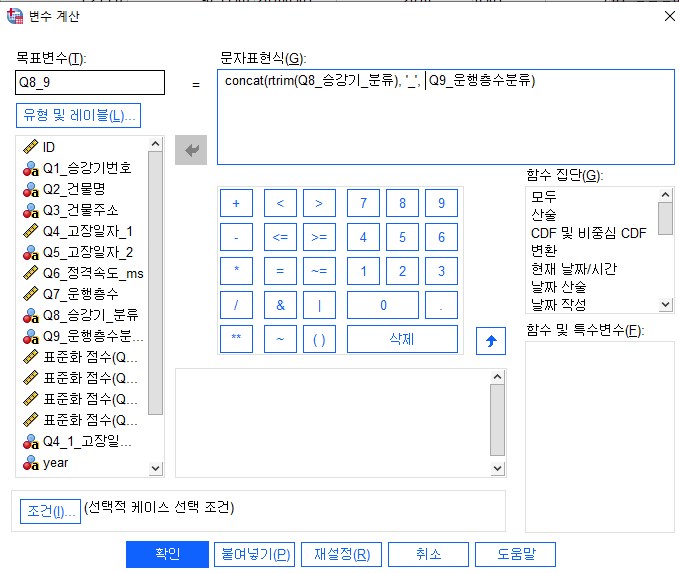
2-2. concat rtrim 10:05
concat rtrim=오른쪽에 있는 해당 문자외에의 것을 제거한다
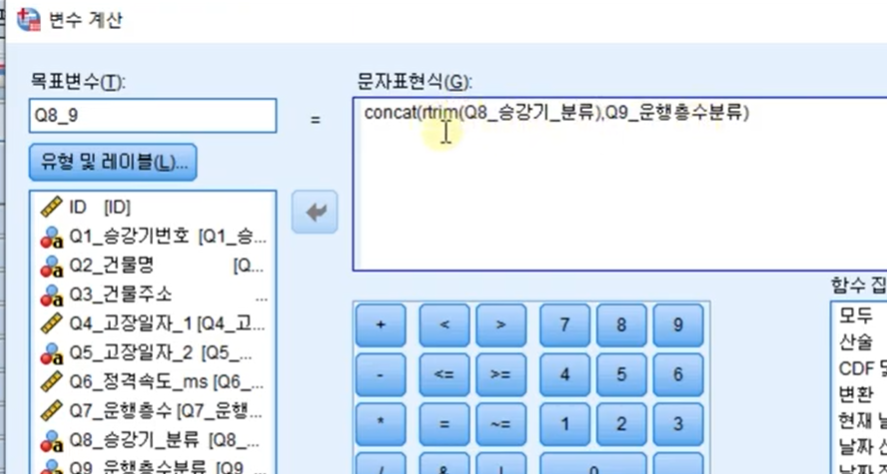
_ 언더바로 구분하고 싶으면
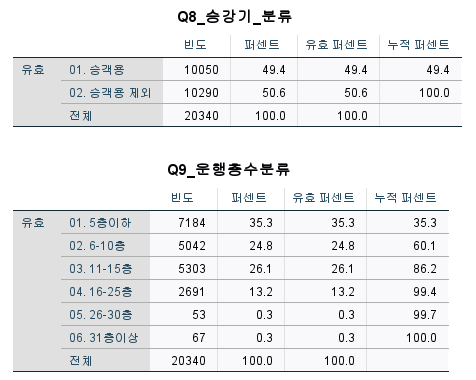
concat(rtrim(Q8_승강기_분류), '_', Q9_운행층수분류)
SPSS 에서 중요한 것은
투입된 데이터의 오른쪽 빈공간을 없애는 것이 중요하다
3. 교차분석 11:52
질적자료 &질적자료 => 교차분석 실행 가능
분석-기술통계량-교차분석
3-1. 행 % 12:40
통계량-카이제곱 무조건 체크 후,
셀- 퍼센트에서 '행'선택
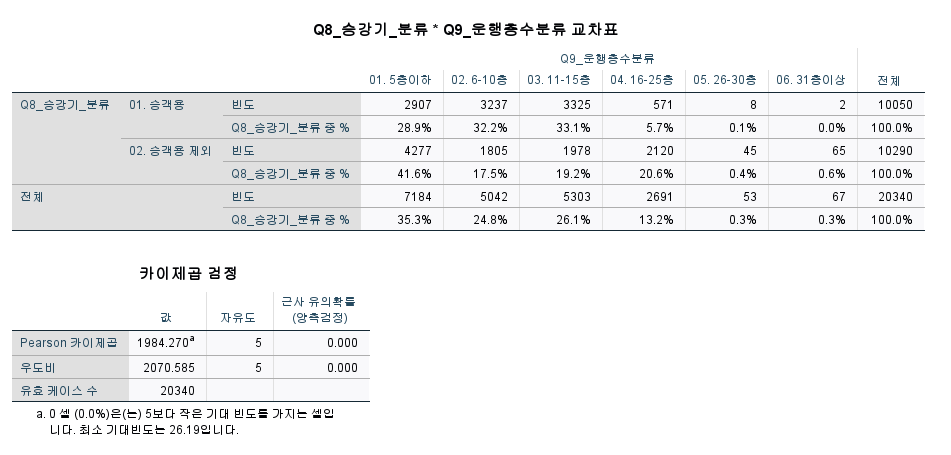
승강기를 기준으로
시험에서는 행이 100으로 나오던지
컬럼이 100으로 나오던지 맞춰서 나올 것
통계량-카이제곱 무조건 체크 후,
셀- 퍼센트에서 '행'선택
3-2. 열 % 13:20
승객용을 100으로 놓고
층수가
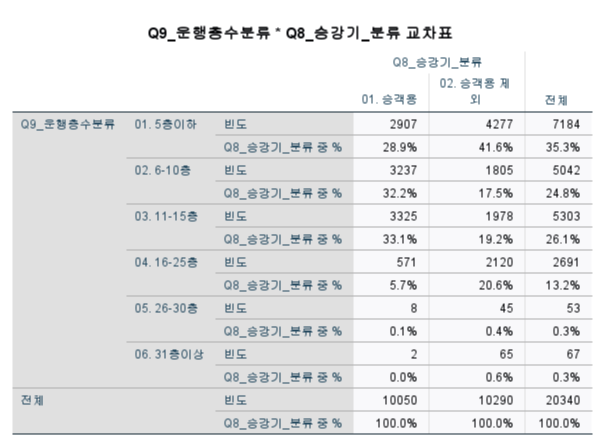
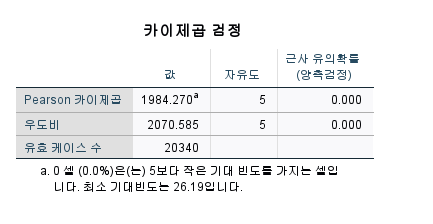
카이제곱 검정을 살펴보았을 때,
행열의 위치를 바꾸더라도
검정통계량이 0.00이므로
독립이다
사회조사분석사 2급 작업형 실습 네번째 동영상입니다.
수록내용:
1. 독립표본 t검정
분석-평균비교-독립표본T검정
양적인 자료가 아닌 경우에는 분산분석과 독립표본t검정이 불가하므로
양적인 자료, 즉 숫자자료로 변환해야함
1:1로 변환> 자동코딩변경(가나다 순으로 정렬되므로 혼란스러움)
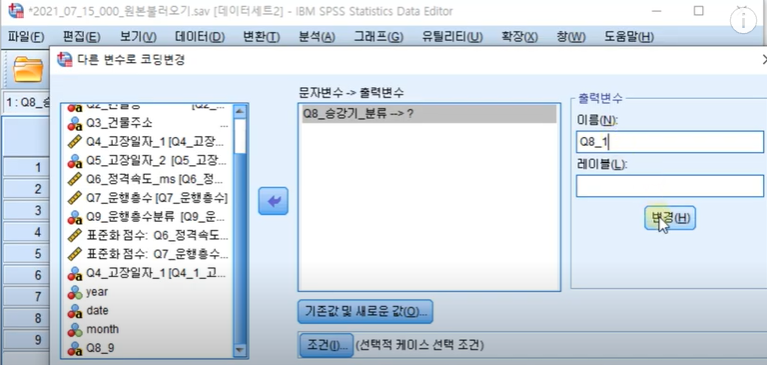
2. 다른변수로 코딩 변경 01:45
변환- 다른 변수로 코딩변경
문자변수->출력변수 부분에 Q8넣고
출력변수 이름 설정
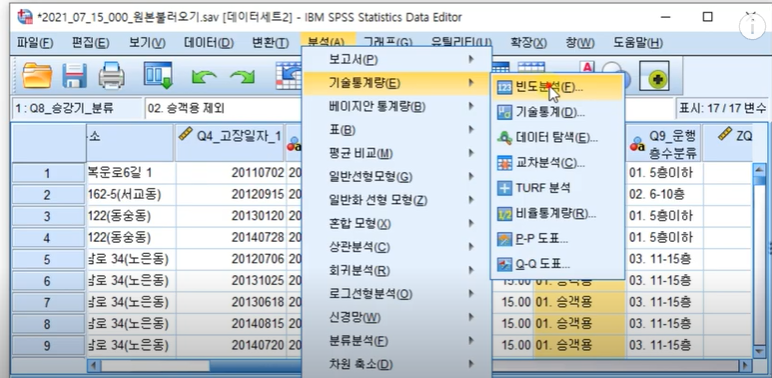
해당부분 빈도분석 먼저 출력해야함
분석-기술통계량-빈도분석
화면상에 해당하는 부분 확인하면서 입력
01. 승객용
02. 승객용 제외
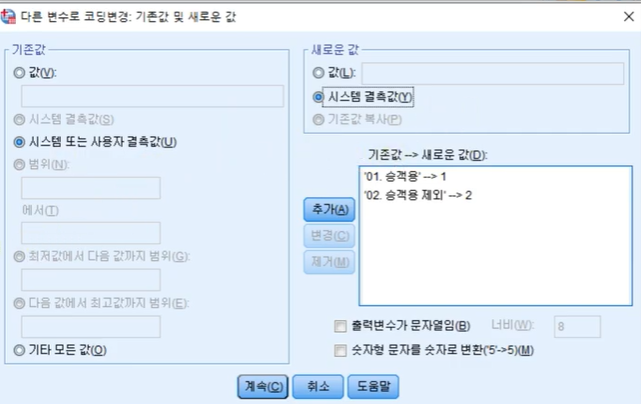
2-1. 다시 문자형의 숫자형 변경
(다른변수로 코딩변경, 시스템 또는 사용자 결측값) 03:00
값부분에 01. 승객용 새로운 값부분에 1
값부분에 02. 승객용 제외 새로운 값부분에 2
마지막에 기존값과 새로운 값 모두에 시스템 결측값으로 설정하기
Q8_1의 값 레이블을 설정하는데
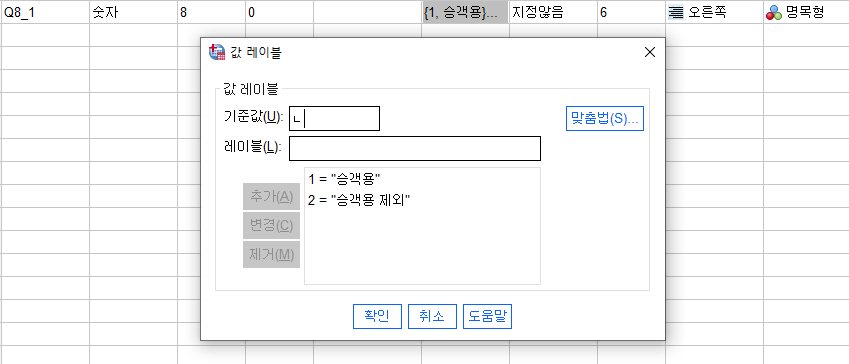
1 =승객용
2=승객용 제외 로 설정
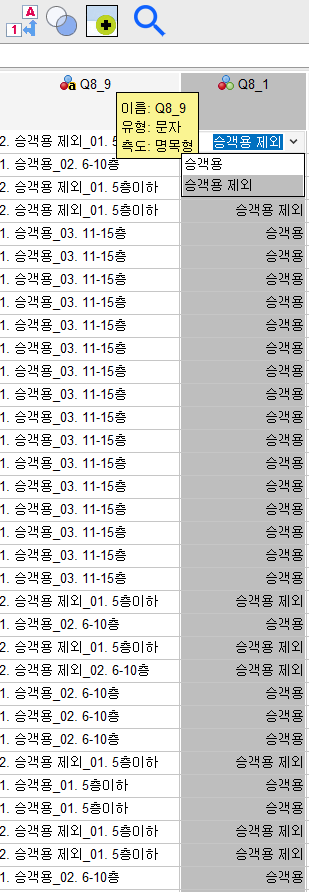
2-2. 문자형 표기를 숫자형으로 변경 04:20
데이터 보기로 했을 때
왼쪽 그림처럼 문자형으로 나온다면 해당부분 클릭하여 숫자형으로 변경가능함
2-3. 자동 코딩 변경 04:35
- 너무 많은 경우
- 이미 가나다순으로 정렬되어있는 경우
변환-자동코딩변경
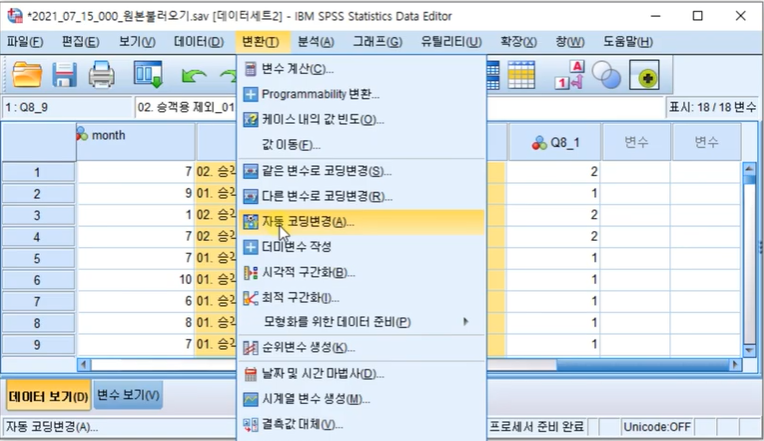
변수-> 새 이름 설정
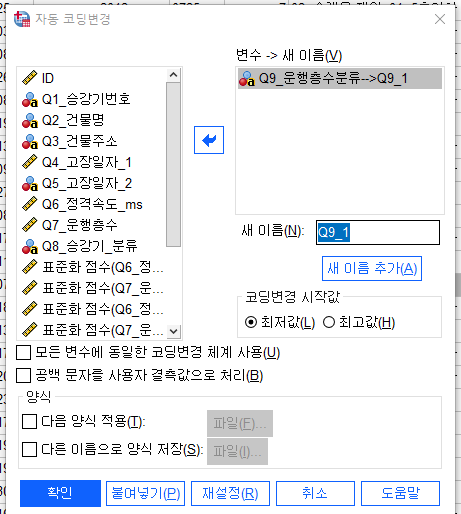
값 레이블 부분에
변수가 알아서 들어가있음
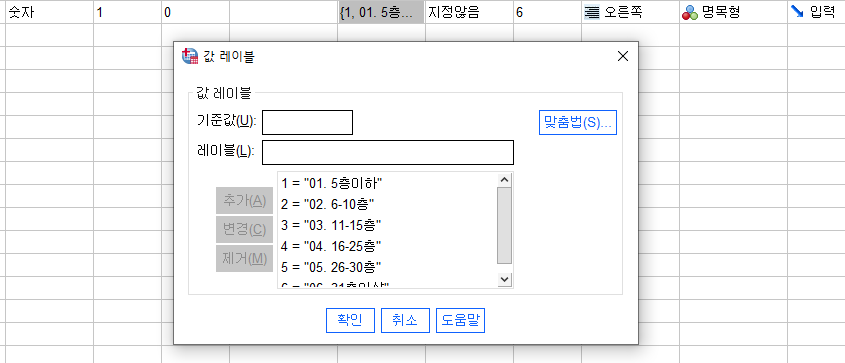
변수변환이 안된다면 문자형으로 되어있는지 확인하기
3. 일표본 t검정 06:15
정말 운행층수가 평균적으로 10층이냐를 확인하기
분석-평균비교-일표본 T검정
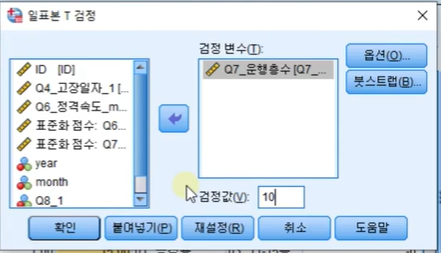
3-1. 주어진 검정 기준 06:30
귀무가설: 10이다
대립가설: 10이 아니다 으로 설정했을 때
유의확률 0.000으로 귀무가설은 기각된다
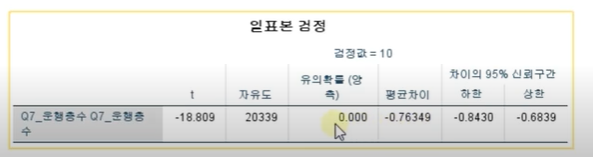
평균 9.2층
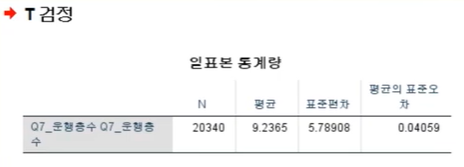
3-2. <0.001로 표기될 경우 해결법 07:35
해당부분을 더블클릭하면
자세한 갑이 나오며
숫자E-숫자 형태는 0.000이라고 할 수 있다

3-2. 신뢰구간 구하기 (신뢰구간 설정하는 방법, 이유) 09:00
신뢰구간은 신뢰구간을 구하라고 할 때만 구하기
분석-평균비교-일표본T검정으로 들어가서
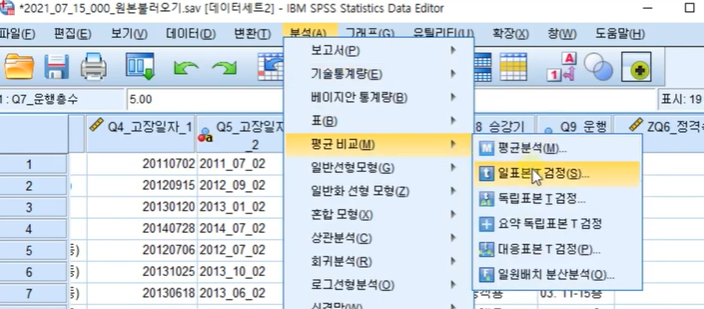
검정값을 0으로 설정하고신뢰구간을 90%으로 변경
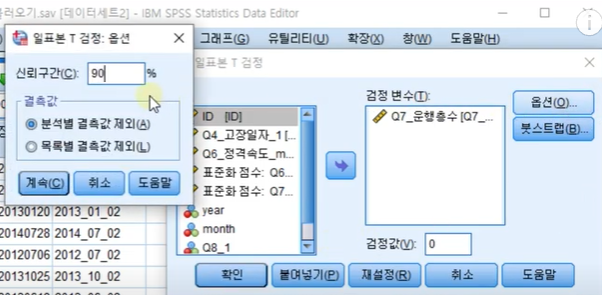
90% 신뢰구간
4. 독립표본 t검정 09:50
독립표본t검정: 두 개 이상의 집단간의 평균비교
일원배치분산분석: 세 개 이상의 집단 간의 평균비교
분석-평균비교-독립표본T검정
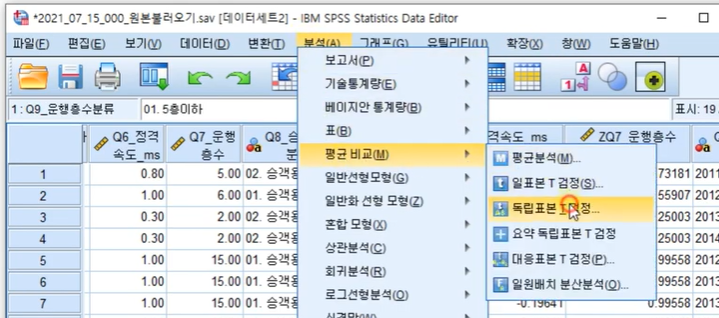
집단변수: Q8_1(운행층수)로 설정한 후
집단정의-지정값 사용
집단1: 1
집단2: 2
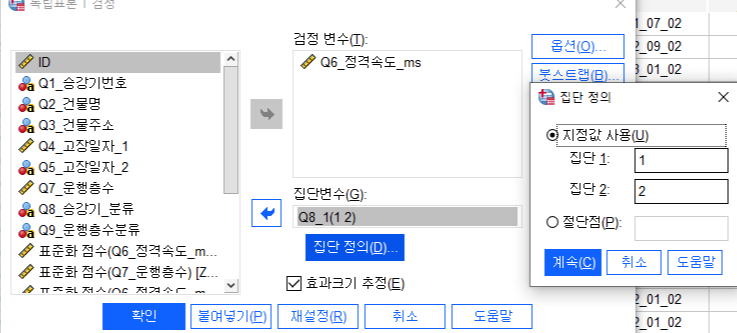
검정 변수: Q6_정격속도
신뢰구간은 시험문제에 주어지지않은 경우 바꿀 필요 없음
해당부분 더블클릭한다음
셀 형식-숫자 & 소수점 셋째자리 이하로 설정
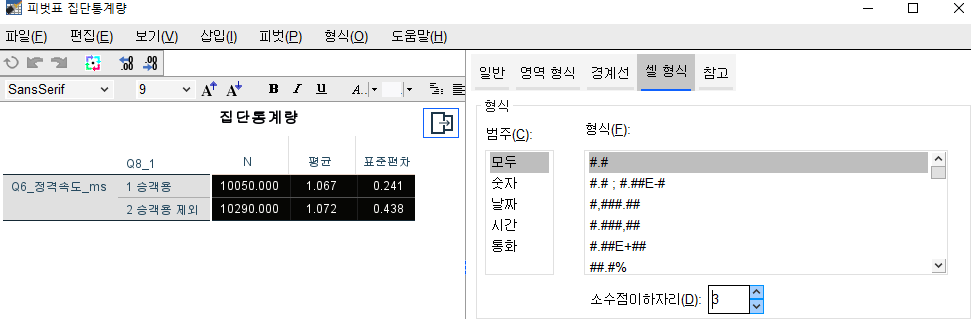
답은 무조건 셋째자리로 구하기
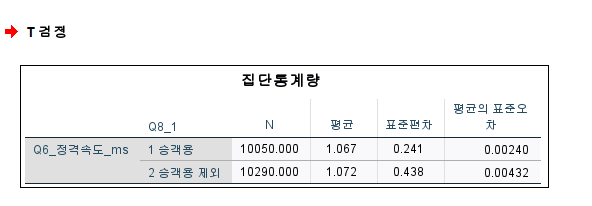
0.000이므로 등분산이 가정X
등분산을 가정하지 않음= 이분산
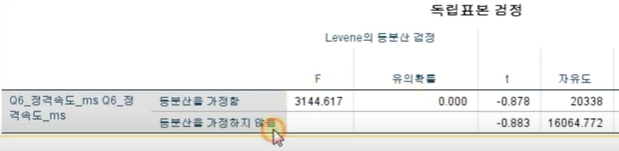
아래부분으로 해석해야함
유의확률 구해야한다
과거 버전은 양측검정만 나오는데
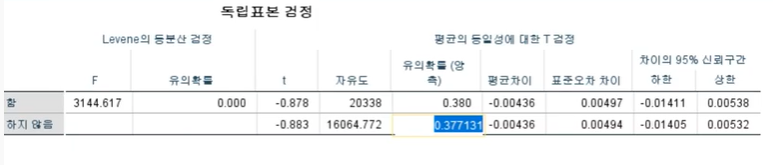
해당부분을 복사하여 새로운 파일에 소수점 여섯째자리까지로 설정한다
소수점 여섯째자리까지 해서 나온 후
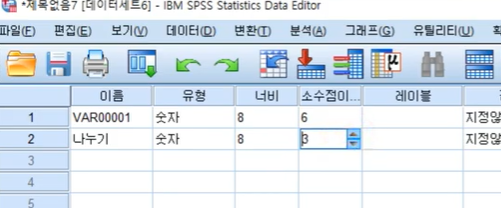
변환-변수 계산
목표변수: 나누기
/2로
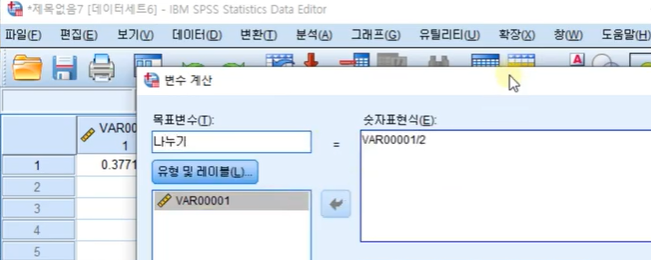
소수점 셋째자리로 변경하여 값구하기
4-1. 단측검정 계산법 12:20
새로운 버전은
양측검정(확률)과 단측 검정(확률)이 알아서 구해짐
새로 구할 필요가 없음

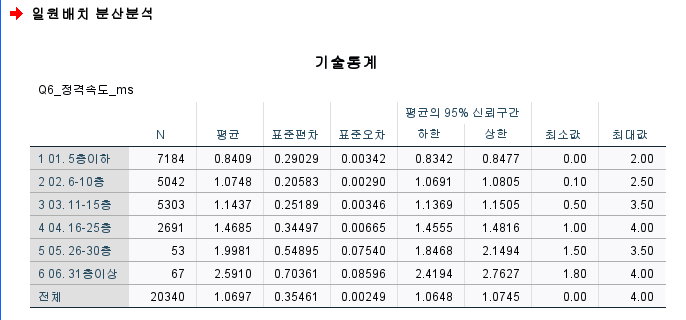
5. (일원배치)분산분석 13:20
분석-평균비교-일원배치 분산분석
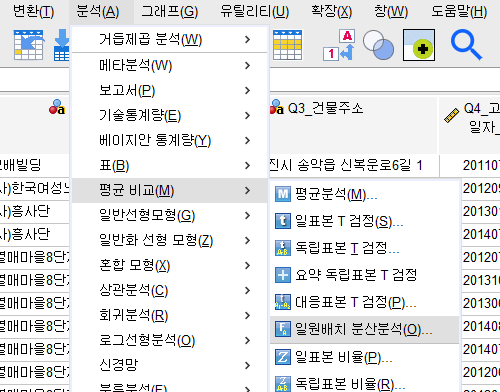
요인부분에 Q9_운행층수분류
종속변수부분에 Q6_정격속도
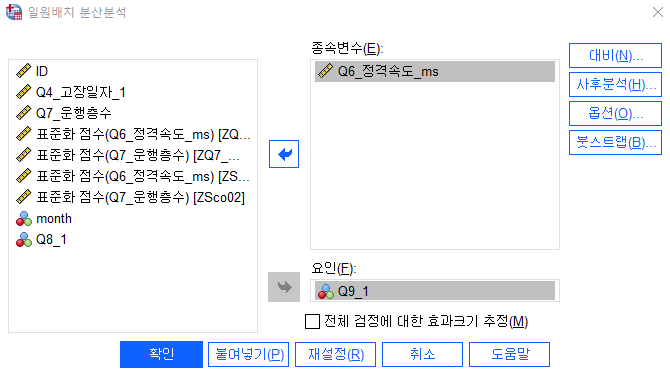
옵션에서
- 기술통계
- 분산 동질성 검정
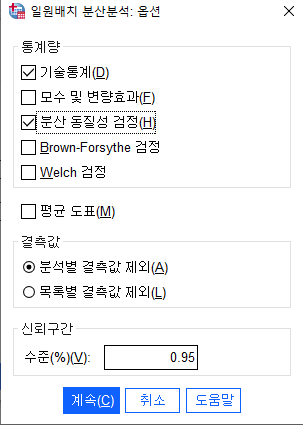
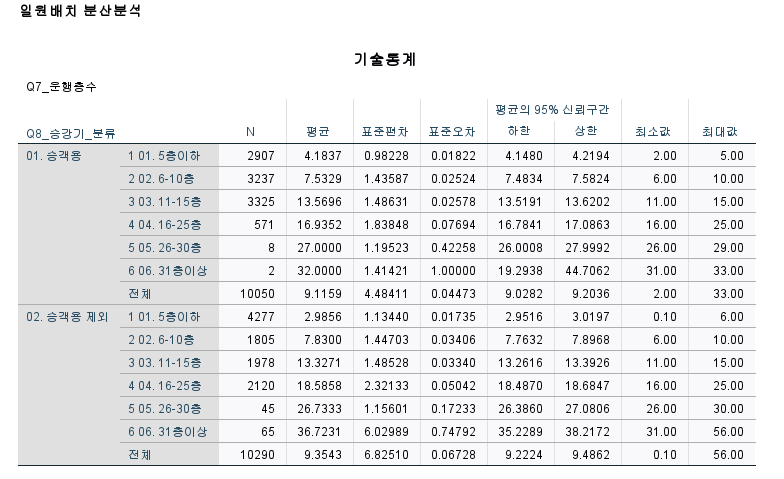
평균, 표준오차 등의 결과 도출
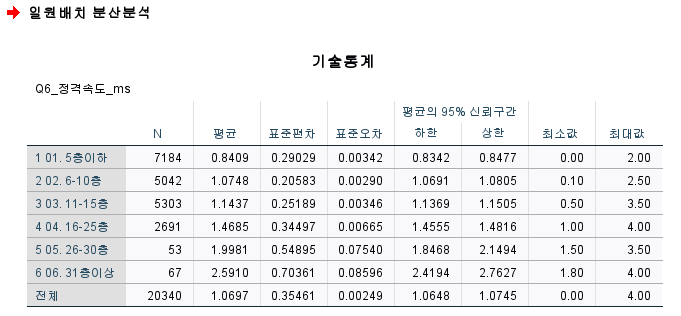
분산의 동질성 검정은 맨위만 확인하면 된다
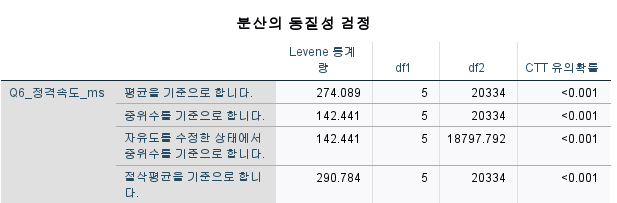
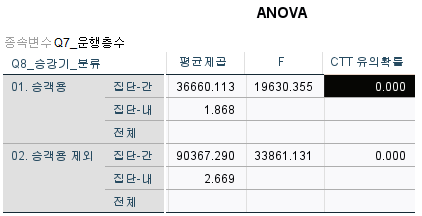
귀무가설: 층별에 따라서 정격속도는 차이가 없다
대립가설: 최소한 하나는 층별에 따라서 정격속도는 차이가 있다
유의확률 0.000이므로 귀무가설은 기각
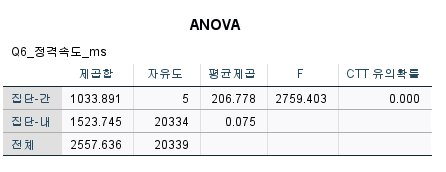
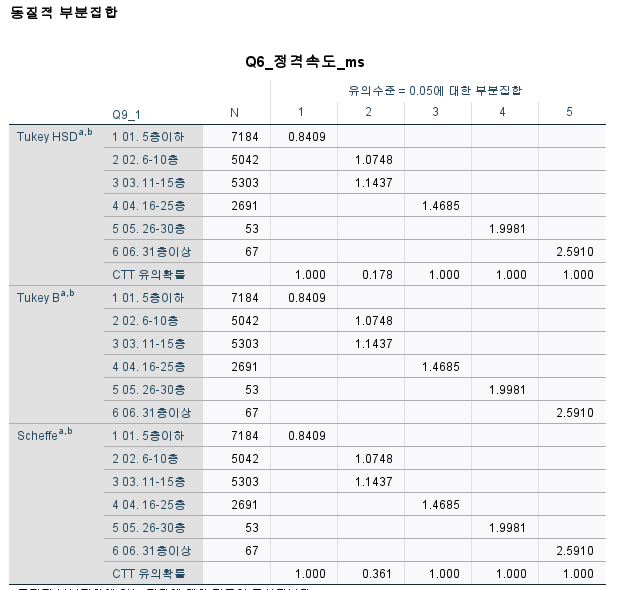
사후분석
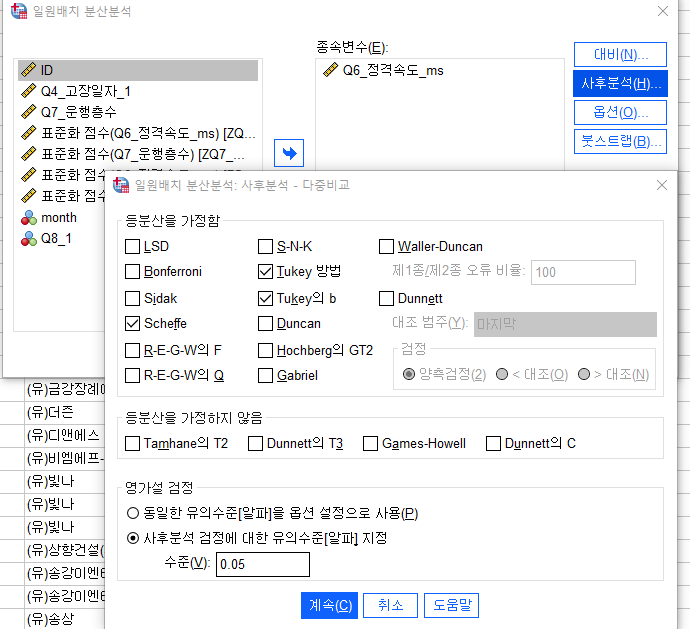
다시 분석-평균 비교- 일원배치 분석분석창으로 들어가서
사후분석에서
Scheffe, Turkey 방법, Turkeydml b 3가지 체크 후
영가설 검정에서 사후분석 검정에 대한 유의수준 지정을 확인하고
동질적 부분집합으로 결과 도출
층이 높아질수록 정격속도가 높아진다
집단간이 확실히 정격속도가 다르다
6. 평균비교 15:45
일원배치분산분석-옵션-기술통계로
해당되는 기술통계량을 구할 수 있음
해당하는 응답건수 2만여개의 부분 건수들을 구할 수 있음
Q7_운행층수를 탑승할 수 있는 인원수라고 가정한다면,
최종적인 합계를 구하는 것이 달라짐
일원배치= 운행층수의 각각의 평균으로 나온다
Q7을 명수라고 생각하고 구하려면
분석-평균 비교-평균 분석
독립변수: Q9_운행층수분류
종속변수: Q7_운행층수
옵션-셀통계량을
- 합계
- 전체 합계의 퍼센트
- 케이스 수
- 전체 N의 퍼센트
- 평균
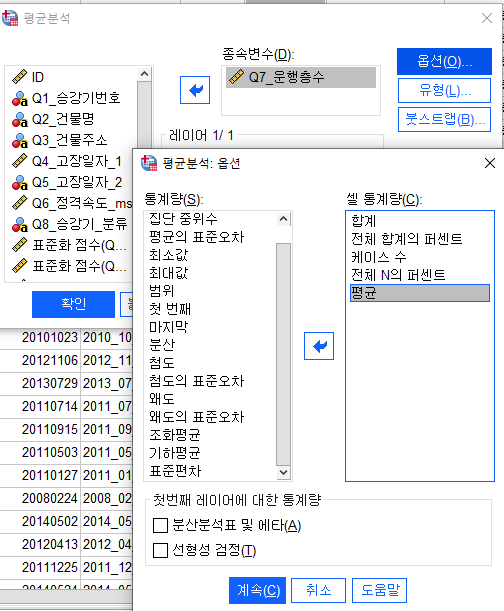
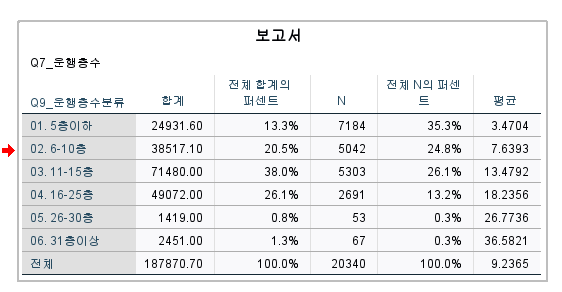
해당 결과 평균이 3.47층으로 도출
이를 분산분석표랑 비교하면
분석-평균 비교- 일원배치 분산분석
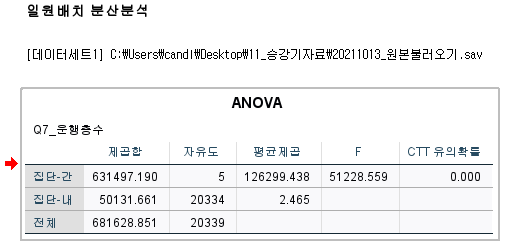
각 해당하는 부분의 합계와
전체합계의 비율을 구하려면
평균비교-평균 분석을 활용해야함
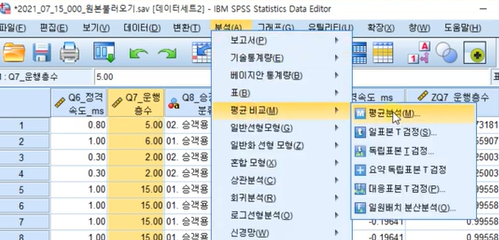
6-1. 분산분석과
평균 비교(일원배치 분산분석) 차이점
사회조사분석사 2급 작업형 실습 다섯번째 기본 마지막 동영상입니다.
수록내용:
1. 텍스트 나누기 00:47
변환-변수계산
재설정을 누른다음
목표변수: Q1_1
유형 및 레이블 문자로 설정하 후 50으로 변경
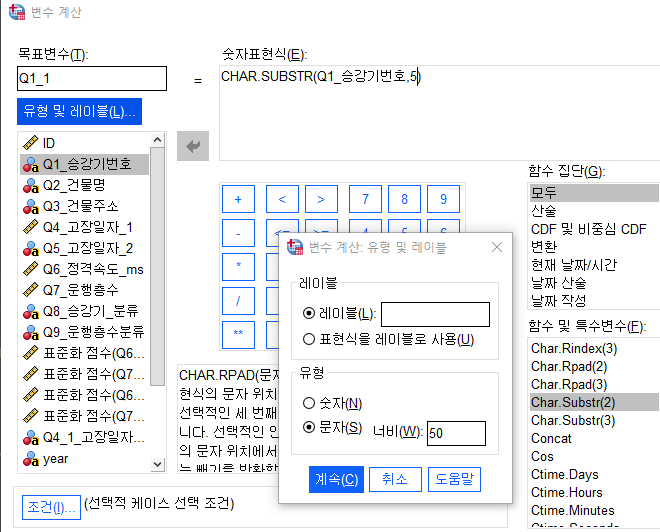
Q1_1을 숫자계산을 하기위해 변수보기에서 숫자형으로 변경

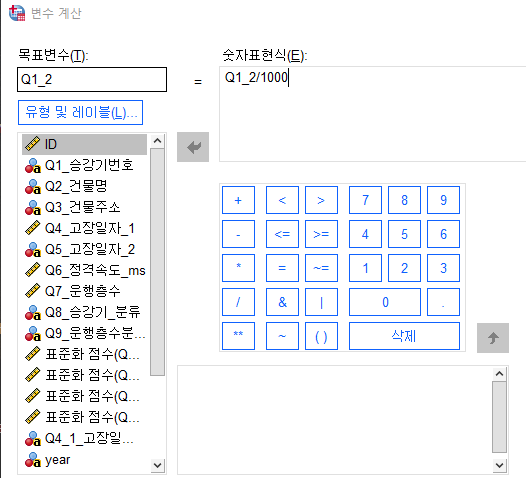
1-1. 숫자형의 나누기 (원 단위를 천원 단위로) 02:22
변수-변수변환
/1000으로 나누고 소수점 셋째자리로 변경

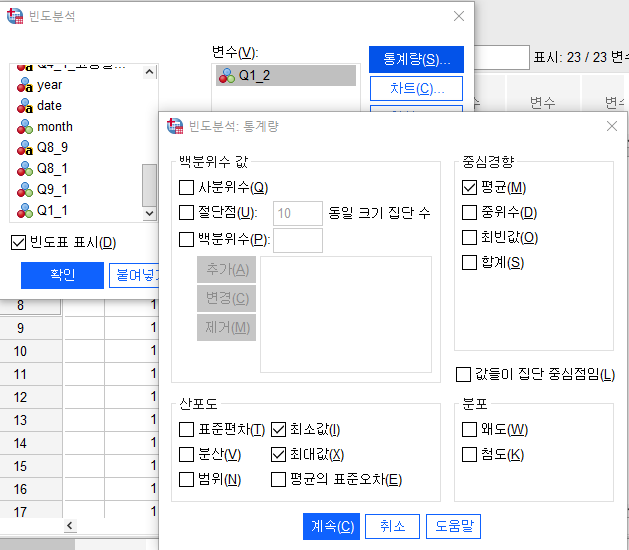
최솟값 최댓값 도출
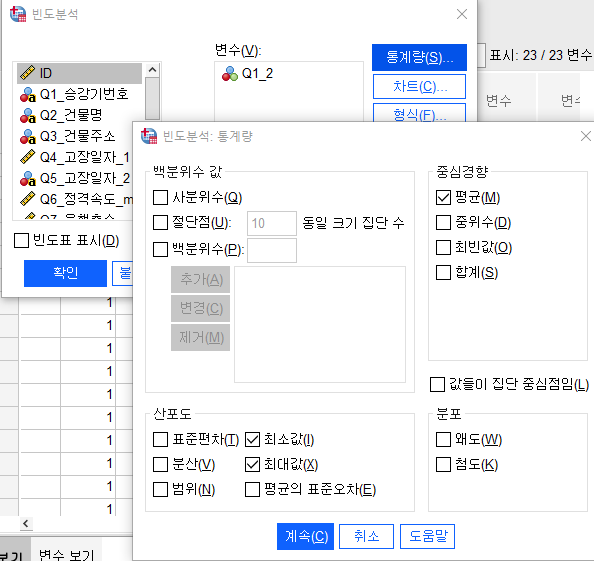
분석-기술통계량-빈도분석
빈도분석 통계량을 평균, 최솟값, 최댓값
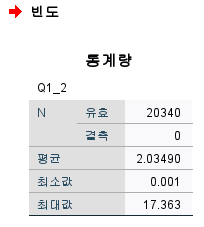
분석결과
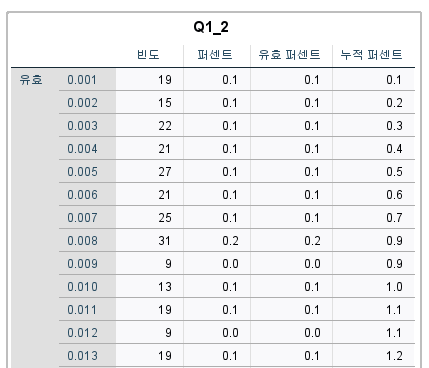
변수보기에서 소수점이 없는 상태에서 똑같이 빈도분석을 돌리면
유효값이 000000
다시 빈도분석을 돌리는데 빈도표 표시 빼고 돌림
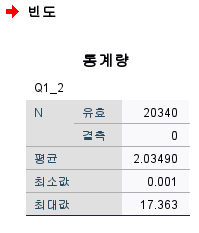
2. 집단 재분류 03:40
2-1. 평균 기준으로 재분류 03:40
평균값보다 작은면 1
평균값보다 크면 2로 그룹분류
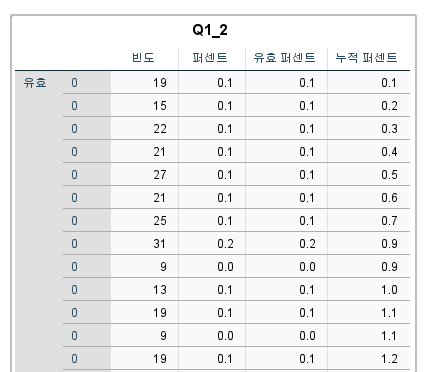
셀 형식에서 소수점 8번째자리로 변경
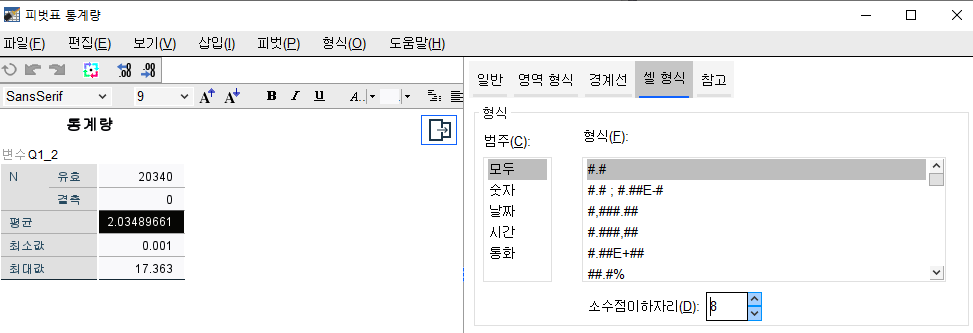
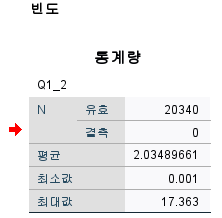
평균 2.03489661 도출
이를 기반으로
0~2.03489661까지는 1그룹
2.03489661~최댓값18까지는 2그룹
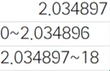
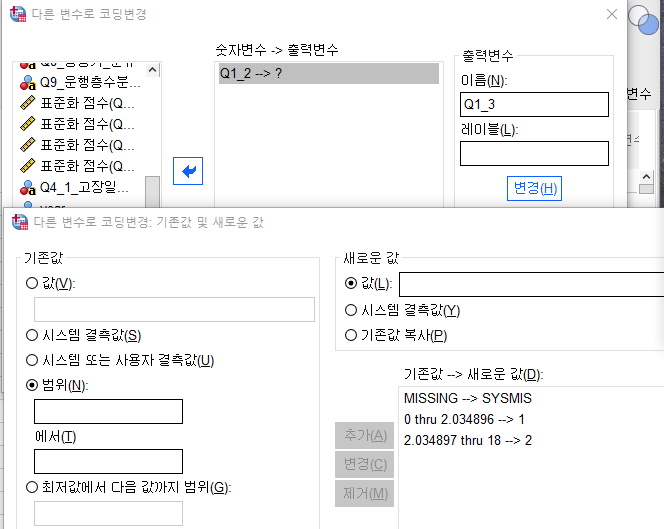
2-2. 다른 변수로 코딩 변경 06:35
변환-다른변수로 코딩변경
재설정한 후 재긓룹

숫자변수-> 출력변수
Q1_2 ->Q1_3
범위: 0에서 2.034896까지
범위: 2.034896에서 값:18까지
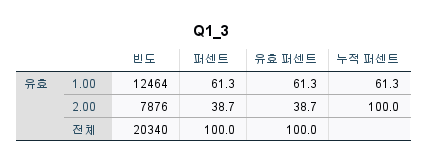
Q1_3을 빈도분석을 돌리면
1집단이 더 많이 차지하믈 알 수 있다
3. 상관분석 08:15
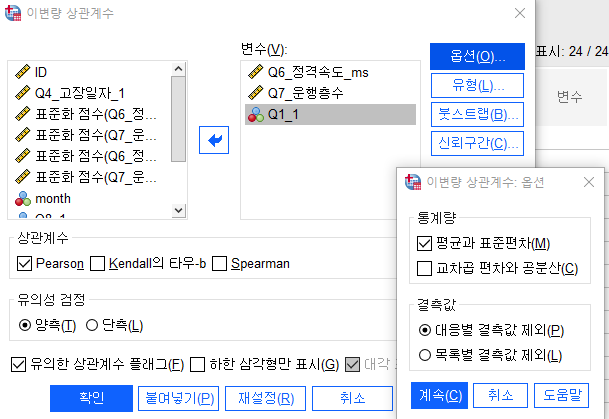
분석-상관분석-이변량 상관
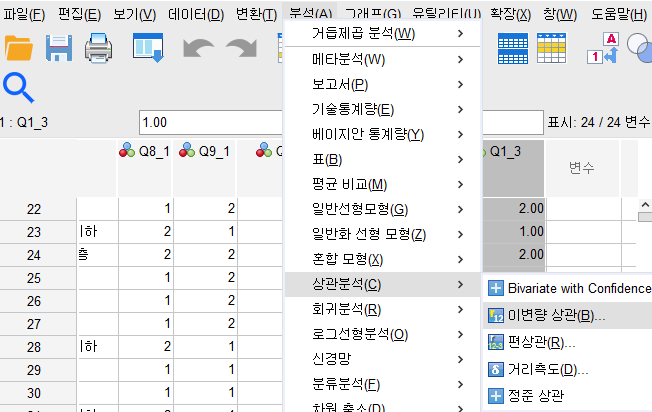
변수: Q6_정격속도, Q7_운행층수, Q1_1로 설정한 후
옵션에서 평균과 표준편차, 대응별 결측값 제외 체크
3-1. 상관분석 해석하기 09:17
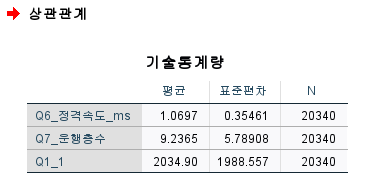
결과로 기술통계량
상관통계량
3-2. 상관분석 * 표기 해석 10:00
0.05보다 작으면 *
0.01보다 작으면 **
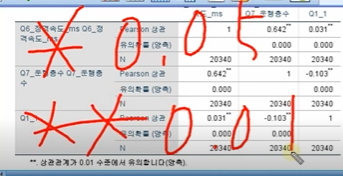
절대값기준이다
3-3. <0.001로 표기될 경우 해결법 11:00
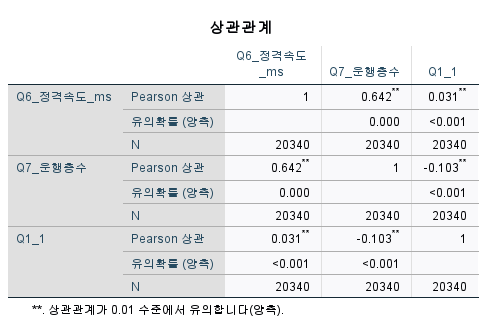
P(0.000)값을 보면
Q6_정격속도와 Q7_운행층수간은 관련성이 있고
상관강도도 매우높다
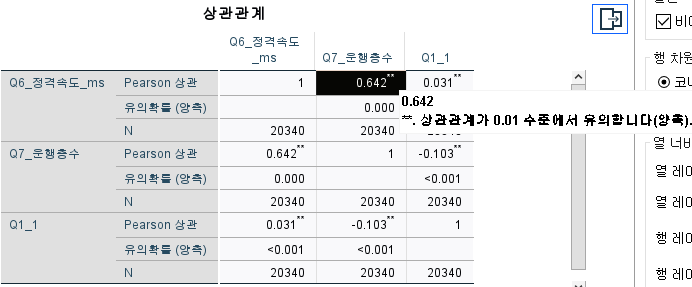
상관관계는 있으나 해당되는 계수값의 강도는 매우 약하다
어떤 값을 기준으로 할 지에 따라 크게 달라짐
꼭 절대값기준으로 해석해야한다!!!!
4. 케이스 선택 12:05
데이터-케이스 선택
4-1. 케이스 선택의 한계점 12:20
숫자형이 아니면 지정할 수 없음
최신부분을 대각선으로 케이스선택했는지 뜨지가 않아 어느부분을 케이스 선택을 했는지 헷갈리게 된다
4-2. 케이스 선택 후 / 표기 안나올 경우 12:40
마우스 우클릭 후 케이스선택이 보이게 선택해야함
5. 가급적이면 파일분할 14:45
집단들 비교, 각 집단별 출력 결과 차이점
데이터-파일분할- 각 집단별로 출력결과를 나타냄
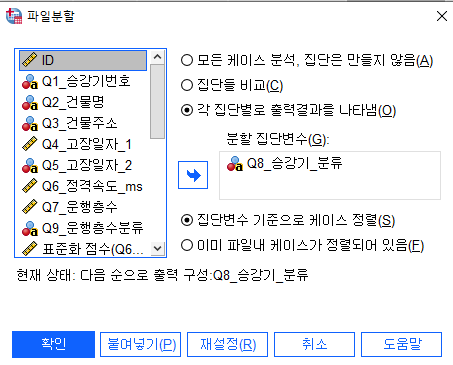
분석-평균비교- 일원배치 분산분석
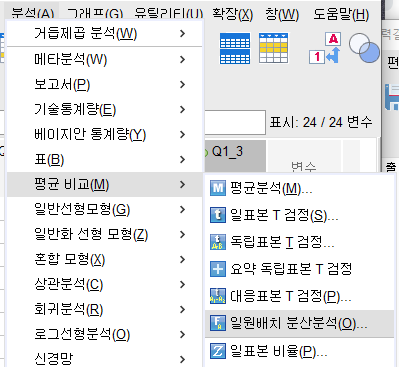
분석결과
각 집단별로 출력결과 나타냄=> 승객용랑 승객용 제외 따로 출력
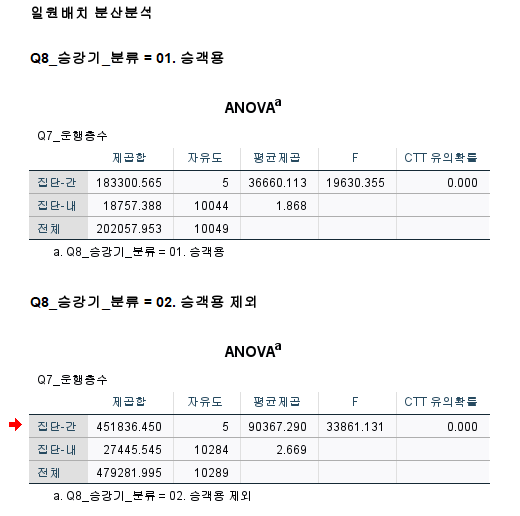
데이터-파일분할- 집단들 비교를 체크하고
다시 분석-평균 비교- 일원배치 분산분석
사후분석은 제거& 옵션-기술통계 체크